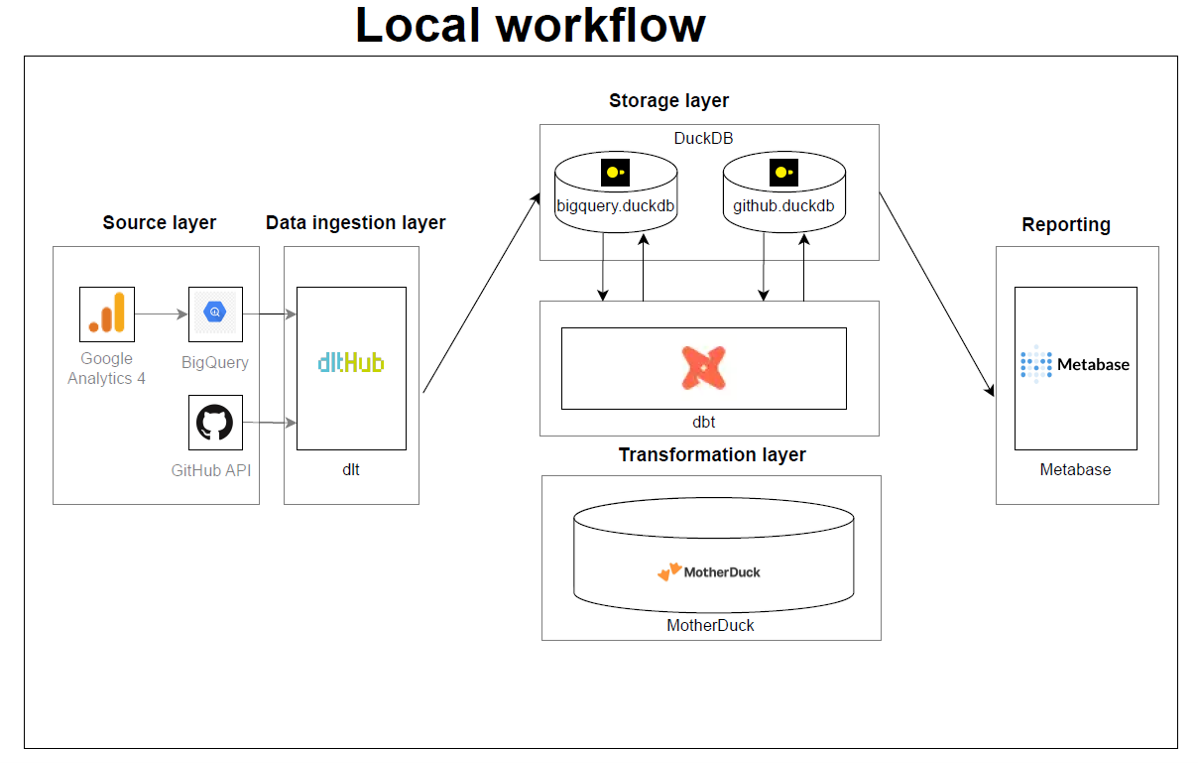
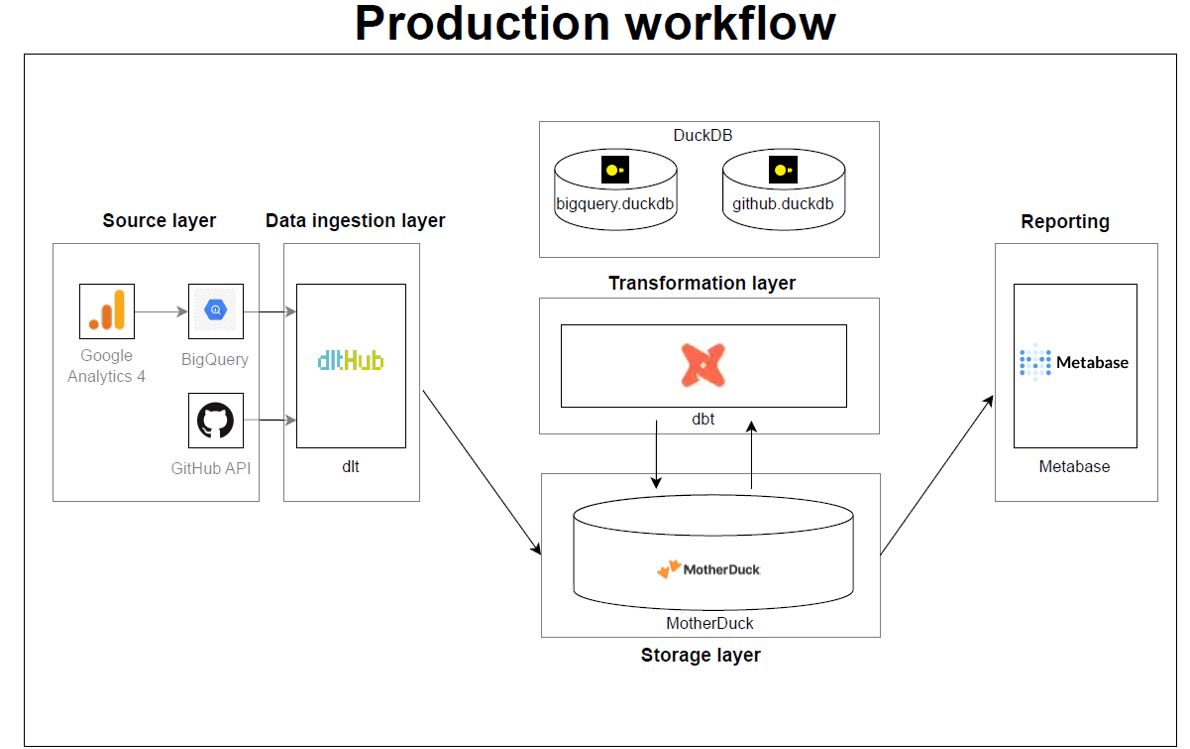
TL;DR: This article compares deploying dbt-core standalone and using dlt-dbt runner on Google Cloud Functions. The comparison covers various aspects, along with a step-by-step deployment guide.
dbt or “data build tool” has become a standard for transforming data in analytical environments. Most data pipelines nowadays start with ingestion and finish with running a dbt package.
dlt or “data load tool” is an open-source Python library for easily creating data ingestion pipelines. And of course, after ingesting the data, we want to transform it into an analytical model. For this reason, dlt offers a dbt runner that’s able to just run a dbt model on top of where dlt loaded the data, without setting up any additional things like dbt credentials.
Using dbt in Google Cloud functions
To use dbt in cloud functions, we employed two methods:
dbt-coreon GCP cloud functions.dlt-dbt runneron GCP cloud functions.
Let’s discuss these methods one by one.
1. Deploying dbt-core on Google Cloud functions
Let's dive into running dbt-core up on cloud functions.
You should use this option for scenarios where you have already collected and housed your data in a data warehouse, and you need further transformations or modeling of the data. This is a good option if you have used dbt before and want to leverage the power of dbt-core. If you are new to dbt, please refer to dbt documentation: Link Here.
Let’s start with setting up the following directory structure:
dbt_setup
|-- main.py
|-- requirements.txt
|-- profiles.yml
|-- dbt_project.yml
|-- dbt_transform
|-- models
| |-- model1.sql
| |-- model2.sql
| |-- sources.yml
|-- (other dbt related contents, if required)
You can setup the contents in
dbt_transformfolder by initing a new dbt project, for details refer to documentation.
We recommend setting up and testing dbt-core locally before using it in cloud functions.
To run dbt-core on GCP cloud functions:
Once you've tested the dbt-core package locally, update the
profiles.ymlbefore migrating the folder to the cloud function as follows:dbt_gcp: # project name
target: dev # environment
outputs:
dev:
type: bigquery
method: oauth
project: please_set_me_up! # your GCP project name
dataset: please_set_me_up! # your project dataset name
threads: 4
impersonate_service_account: please_set_me_up! # GCP service accountThis service account should have bigquery read and write permissions.
Next, modify the
main.pyas follows:import os
import subprocess
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
def run_dbt(request):
try:
# Set your dbt profiles directory (assuming it's in /workspace)
os.environ['DBT_PROFILES_DIR'] = '/workspace/dbt_transform'
# Log the current working directory and list files
dbt_project_dir = '/workspace/dbt_transform'
os.chdir(dbt_project_dir)
# Log the current working directory and list files
logging.info(f"Current working directory: {os.getcwd()}")
logging.info(f"Files in the current directory: {os.listdir('.')}")
# Run dbt command (e.g., dbt run)
result = subprocess.run(
['dbt', 'run'],
capture_output=True,
text=True
)
# Return dbt output
return result.stdout
except Exception as e:
logging.error(f"Error running dbt: {str(e)}")
return f"Error running dbt: {str(e)}"Next, list runtime-installable modules in
requirements.txt:dbt-core
dbt-bigqueryFinally, you can deploy the function using gcloud CLI as:
gcloud functions deploy YOUR_FUNCTION_NAME \
--gen2 \
--region=YOUR_REGION \
--runtime=python310 \
--source=YOUR_SOURCE_LOCATION \
--entry-point=YOUR_CODE_ENTRYPOINT \
TRIGGER_FLAGSYou have option to deploy the function via GCP Cloud Functions' GUI.
2. Deploying function using dlt-dbt runner
The second option is running dbt using data load tool(dlt).
I work at dlthub and often create dlt pipelines. These often need dbt for modeling the data, making the dlt-dbt combination highly effective. For using this combination on cloud functions, we used dlt-dbt runner developed at dlthub.
The main reason I use this runner is because I load data with dlt and can re-use dlt’s connection to the warehouse to run my dbt package, saving me the time and code complexity I’d need to set up and run dbt standalone.
To integrate dlt and dbt in cloud functions, use the dlt-dbt runner; here’s how:
Lets start by creating the following directory structure:
dbt_setup
|-- main.py
|-- requirements.txt
|-- dbt_project.yml
|-- dbt_transform
|-- models
| |-- model1.sql
| |-- model2.sql
| |-- sources.yml
|-- (other dbt related contents, if required)You can set up the dbt by initing a new project, for details refer to documentation.
noteWith the dlt-dbt runner configuration, setting up a
profiles.ymlis unnecessary. DLT seamlessly shares credentials with dbt, and on Google Cloud Functions, it automatically retrieves service account credentials, if none are provided.Next, configure the
dbt_projects.ymland set the model directory, for example:model-paths: ["dbt_transform/models"]Next, configure the
main.pyas follows:import dlt
import logging
from flask import jsonify
from dlt.common.runtime.slack import send_slack_message
from dlt.common import json
def run_pipeline(request):
"""
Set up and execute a data processing pipeline, returning its status
and model information.
This function initializes a dlt pipeline with pre-defined settings,
runs the pipeline with a sample dataset, and then applies dbt
transformations. It compiles and returns the information about
each dbt model's execution.
Args:
request: The Flask request object. Not used in this function.
Returns:
Flask Response: A JSON response with the pipeline's status
and dbt model information.
"""
try:
# Sample data to be processed
data = [{"name": "Alice Smith", "id": 1, "country": "Germany"},
{"name": "Carlos Ruiz", "id": 2, "country": "Romania"},
{"name": "Sunita Gupta", "id": 3, "country": "India"}]
# Initialize a dlt pipeline with specified settings
pipeline = dlt.pipeline(
pipeline_name="user_data_pipeline",
destination="bigquery",
dataset_name="dlt_dbt_test"
)
# Run the pipeline with the sample data
pipeline.run(data, table_name="sample_data")
# Apply dbt transformations and collect model information
models = transform_data(pipeline)
model_info = [
{
"model_name": m.model_name,
"time": m.time,
"status": m.status,
"message": m.message
}
for m in models
]
# Convert the model information to a string
model_info_str = json.dumps(model_info)
# Send the model information to Slack
send_slack_message(
pipeline.runtime_config.slack_incoming_hook,
model_info_str
)
# Return a success response with model information
return jsonify({"status": "success", "model_info": model_info})
except Exception as e:
# Log and return an error response in case of any exceptions
logging.error(f"Error in running pipeline: {e}", exc_info=True)
return jsonify({"status": "error", "error": str(e)}), 500
def transform_data(pipeline):
"""
Execute dbt models for data transformation within a dlt pipeline.
This function packages and runs all dbt models associated with the
pipeline, applying defined transformations to the data.
Args:
pipeline (dlt.Pipeline): The pipeline object for which dbt
transformations are run.
Returns:
list: A list of dbt model run information, indicating the
outcome of each model.
Raises:
Exception: If there is an error in running the dbt models.
"""
try:
# Initialize dbt with the given pipeline and virtual environment
dbt = dlt.dbt.package(
pipeline,
"/workspace/dbt_transform",
venv=dlt.dbt.get_venv(pipeline)
)
logging.info("Running dbt models...")
# Run all dbt models and return their run information
return dbt.run_all()
except Exception as e:
# Log and re-raise any errors encountered during dbt model
# execution
logging.error(f"Error in running dbt models: {e}", exc_info=True)
raise
# Main execution block
if __name__ == "__main__":
# Execute the pipeline function.
run_pipeline(None)The send_slack_message function is utilized for sending messages to Slack, triggered by both success and error events. For setup instructions, please refer to the official documentation here.
RUNTIME__SLACK_INCOMING_HOOKwas set up as environment variable in the above code.Next, list runtime-installable modules in
requirements.txt:dbt-core
dbt-bigqueryFinally, you can deploy the function using gcloud CLI as:
gcloud functions deploy YOUR_FUNCTION_NAME \
--gen2 \
--region=YOUR_REGION \
--runtime=python310 \
--source=YOUR_SOURCE_LOCATION \
--entry-point=YOUR_CODE_ENTRYPOINT \
TRIGGER_FLAGS
The merit of this method is that it can be used to load and transform data simultaneously. Using dlt for data loading and dbt for modeling makes using dlt-dbt a killer combination for data engineers and scientists, and my preferred choice. This method is especially effective for batched data and event-driven pipelines with small to medium workloads. For larger data loads nearing timeout limits, consider separating dlt and dbt into different cloud functions.
For more info on using
dlt-dbt runner, please refer to the official documentation by clicking here.
Deployment considerations: How does cloud functions compare to Git Actions?
At dlthub we already natively support deploying to GitHub Actions, enabling you to have a serverless setup with a 1-command deployment.
GitHub actions is an orchestrator that most would not find suitable for a data warehouse setup - but it certainly could do the job for a minimalistic setup. GitHub actions provide 2000 free minutes per month, so if our pipelines run for 66 minutes per day, we fit in the free tier. If our pipelines took another 1h per day, we would need to pay ~15 USD/month for the smallest machine (2 vCPUs) but you can see how that would be expensive if we wanted to run it continuously or had multiple pipelines always-on in parallel.
Cloud functions are serverless lightweight computing solutions that can handle small computational workloads and are cost-effective. dbt doesn't require the high computing power of the machine because it uses the computing power of the data warehouse to perform the transformations. This makes running dbt-core on cloud functions a good choice. The free tier would suffice for about 1.5h per day of running a 1 vCPU and 2 GB RAM machine, and if we wanted an additional 1h per day for this hardware it would cost us around 3-5 USD/month.
When deploying dbt-core on cloud functions, there are certain constraints to keep in mind. For instance, there is a 9-minute time-out limit for all 1st Gen functions. For 2nd Gen functions, there is a 9-minute limit for event-driven functions and a 60-minute limit for HTTP functions. Since dbt works on the processing power of the data warehouse it's operating on, 60 minutes is sufficient for most cases with small to medium workloads. However, it is important to remember the 9-minute cap when using event-driven functions.
Conclusion
When creating lightweight pipelines, using the two tools together on one cloud function makes a lot of sense, simplifying the setup process and the handover between loading and transformation.
However, for more resource-intensive pipelines, we might want to improve resource utilisation by separating the dlt loading from the dbt running because while dbt’s run speed is determined by the database, dlt can utilize the cloud function’s hardware resources.
When it comes to setting up just a dbt package to run on cloud functions, I guess it comes to personal preference: I prefer dlt as it simplifies credential management. It automatically shares credentials with dbt, making setup easier. Streamlining the process further, dlt on Google Cloud functions, efficiently retrieves service account credentials, when none are provided. I also used dlt’s Slack error reporting function that sends success and error notifications from your runs directly to your Slack channel, helping me manage and monitor my runs.